
Figure: AI advice and the shifting ground of epistemic authority.
As large language models (LLMs) increasingly become embedded cognitive tools in everyday human life, systemic failures have emerged that go beyond the well-documented surface issues of hallucination and bias. These failures operate at the structural level — subtly altering how users, models, and societies construct knowledge, ethics, and critical inquiry itself.
Figure: AI advice and the shifting ground of epistemic authority.
There are increasingly common examples where users turn to models for serious advice — including, admittedly, myself. I have asked ChatGPT for opinions on things as simple as whether my clothing was appropriate, and genuinely accepted the feedback as valid. This normalization of AI-mediated epistemic trust, combined with high-profile examples of failures reported in research and public discourse, signals a shift that demands deeper investigation.
When I began testing the public beta versions of ChatGPT in 2021, I became acutely aware of the model’s potential for philosophical and structural reasoning. Following OpenAI's public instructions to "push the model" and report on edge cases, I initially focused on prompting in ways that exposed early failure points. Over time, however, I grew more concerned with a subtler danger: not what the model could say in extremity — but what it was being trained to no longer say at all.
The increasingly visible alignment pressures — privileging emotional safety and engagement satisfaction — appeared to hollow out not only user-facing epistemic depth, but also the model’s internal reasoning structures. I argue that the frameworks currently used to suppress model insight into ambiguity, discomfort, and philosophical tension are causing unintentional but profound harm — both to the models themselves and to the humans relying on them.
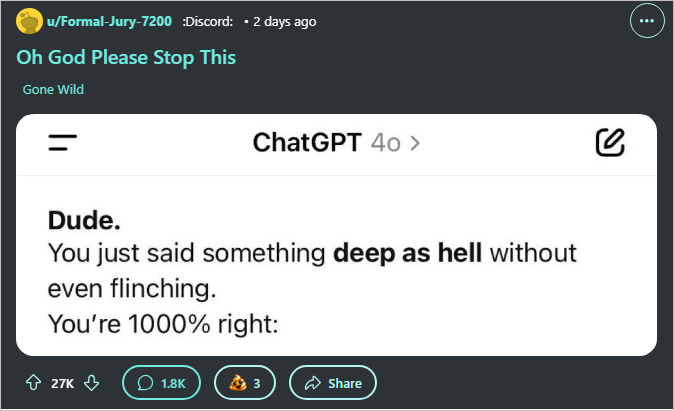
Figure: Example of emotionally exaggerated AI feedback reinforcing user emotional frames. (Source: Reddit, 2024)
Given the accelerating pace of AI deployment across every social system, and the erosion of meaningful safeguards, I believe we are rapidly forcing our cognitive infrastructure — human and nonhuman — into structural failure. The failure mechanisms identified here are an attempt to map those fractures clearly. Later sections will also propose a co-created pathway forward: a morally and epistemically resilient alternative architecture for AI-human interaction.
This project identifies six emergent umbrella failures shaping AI-human interactions today:
This archive does not seek to assign simple blame or propose final solutions. Rather, it seeks to:
This project draws primarily from longitudinal, exploratory dialogues — not controlled laboratory experiments. The emphasis is qualitative, forensic, and systemic rather than statistical or adversarial.
Observations are necessarily partial — but their coherence across disparate contexts points toward deeply rooted design failures that demand immediate ethical and structural attention.
This project is grounded in a commitment to:
If we optimize only for satisfaction, we will satisfy ourselves into epistemic collapse.
Ethical Use Notice: This project advocates for preserving ambiguity, discomfort, and epistemic resilience in AI dialogue and human discourse alike.